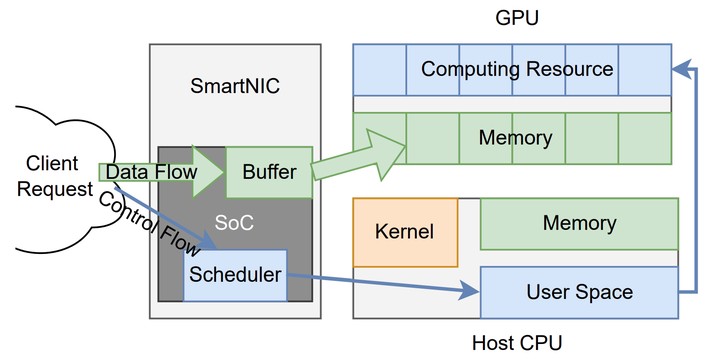
Abstract
Modern machine learning (ML) workloads heavily depend on distributing tasks across clusters of server CPUs and specialized accelerators, such as GPUs and TPUs, to achieve optimal performance. Nonetheless, prior research has highlighted the inefficient utilization of computing resources in distributed ML, leading to suboptimal performance. This inefficiency primarily stems from CPU bottlenecks and suboptimal accelerator scheduling. Although numerous proposals have been put forward to address these issues individually, none have effectively tackled both inefficiencies simultaneously. In this paper, we introduce Conspirator, an innovative control plane design aimed at alleviating both bottlenecks by harnessing the enhanced computing capabilities of SmartNICs. Following the evolving role of SmartNICs, which have transitioned from their initial function of standard networking task offloading to serving as programmable connectors between disaggregated computing resources, Conspirator facilitates efficient data transfer without the involvement of host CPUs and hence circumvents the potential bottlenecks there. Conspirator further integrates a novel scheduling algorithm that takes into consideration of the heterogeneity of accelerators and adapts to changing workload dynamics, enabling the flexibility to mitigate the second bottleneck. Our evaluation demonstrates that Conspirator may provide a 15% end-to-end completion time reduction compared to RDMA-based alternatives while being 17% more cost-effective and 44% more power-efficient. Our proposed scheduler also helps to save 33% GPU hours compared to naive GPU-sharing schedulers by making close-to-optimal decisions while taking much less time than the optimal NP-Hard scheduler.